
Las expresiones regulares son secuencias de caracteres que forman un patrón de búsqueda. Se utilizan principalmente para la búsqueda de patrones de cadenas de caracteres o en sustituciones. Aunque ya abordamos el tema usando grep en Bash, Python provee otras herramientas más versátiles que nos facilitarán la tarea.
Es importante aclarar que además del tratamiento de expresiones regulares que presentamos en este post, Python incluye otros módulos especialmente dedicados a la manipulación de direcciones de correo electrónico.
Manipulación de texto usando expresiones regulares en Python
Para empezar, supongamos que deseemos chequear si una cadena de texto dada representa una dirección de correo electrónico válida del tipo .com.ar. De ser así, la misma tendrá la forma
usuario@ejemplo.com.ar
Como podemos observar, necesitamos detectar la presencia del caracter @ por un lado y de la cadena .com.ar al final. También, para simplificar vamos a suponer que el string que representa al usuario está compuesto solamente por caracteres alfanuméricos. Es decir, no tendremos en cuenta los guiones medio o bajo, el punto, o el signo +, los cuales en realidad son válidos a la izquierda de @.
El siguiente código Python realiza las tareas solicitadas:
email = 'aguantecla@hotmail.com.ar'
if '@' in email: # Chequear que @ esté presente
ubicacionArroba = email.find('@') # Identificar la posición de @
if email[len(email)-7:]=='.com.ar': # Chequear que los últimos 7 caracteres sean '.com.ar'
usuario = email[0:ubicacionArroba] # Extraer la cadena a la izquierda de @
if usuario.isalnum(): # Chequear que usuario sea una cadena alfanumérica
print(email + ' - ' + 'Dirección correcta')
else:
print(usuario + ' - ' + 'Usuario no válido')
else:
print(email + ' - ' + 'Dominio incorrecto')
else:
print(email + ' - ' + 'Dirección incorrecta')
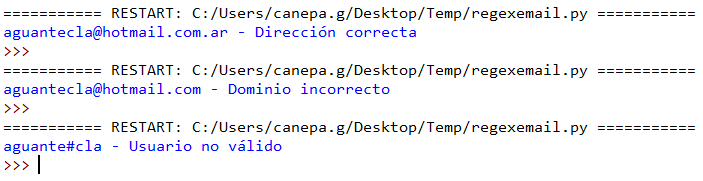
Veamos en la Fig. 1 qué sucede al ejecutar el código de arriba asignándole los siguientes valores a la variable email:
aguantecla@hotmail.com.ar
aguantecla@hotmail.com
aguante#cla@hotmail.com.ar
Sin embargo, hay una forma más fácil y directa de llevar a cabo la detección. Para hacerlo, utilizaremos el módulo re (de regular expressions) de la siguiente manera:
import re email1 = 'holaa.todos@dominio.com.ar' emailRegex = r'(^[\w]+)@([\w]+)' + '.com.ar' match = re.search(emailRegex, email1) if match: print(email1 + ' es una dirección válida.') else: print(email1 + ' no es una dirección válida.')
Análisis del ejemplo
El contenido de la variable emailRegex es un raw string compuesto por los siguientes elementos:
- ^ indica que la expresión regular debe evaluarse en el comienzo de la cadena de texto.
- Para cumplir con la expresión regular, la cadena de texto debe incluir al principio caracteres alfanuméricos (denotados por [\w]) seguida por el caracter @. Luego de @, debe aparecer otra cadena alfanumérica.
- El signo + se utiliza para verificar la presencia de uno o más caracteres alfanuméricos a fin de que cadenas del tipo @dominio.com.ar (sin usuario) u hola@.com.ar (dominio incompleto) sean detectadas como inválidas.
- Finalmente, la cadena de texto debe finalizar en .com.ar.
En Python, un raw string es una cadena de texto en la que los caracteres de escape no son tratados como tales sino como parte integral del texto.
Veamos en la Fig. 2 el resultado del ejemplo anterior (utilizando las mismas direcciones de correo electrónico que antes):
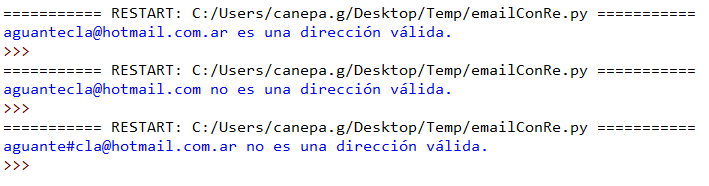
En conclusión, al comparar este ejemplo con el de la sección anterior vemos que es mucho más fácil utilizar el módulo re y expresiones regulares que tener que detectarlas utilizando otras técnicas.
Espero que este post les haya resultado de utilidad. En la documentación de Python sobre expresiones regulares pueden encontrar más detalles si quieren ir anticipándose a próximos posts. (Sugerencia: en este link continuamos hablando sobre el tema).