
En algunos posts anteriores hablamos sobre varias herramientas que pueden sernos de gran utilidad a la hora de procesar o manejar archivos de texto en Linux (por ejemplo, el comando cut). Si bien las mismas pueden llegar a ser muy versátiles y podemos combinarlas con otras mediante el uso de tuberías, podemos llegar a encontrarnos con ciertas limitaciones, o encontrar una manera más robusta de llevar a cabo la misma tarea. Ahí es donde entra awk en la competencia, y es lo que trataremos en este post y en el próximo.
¿Qué es awk?
Estrictamente hablando, awk es un lenguaje de programación en sí (aunque en lo personal lo he visto en uso estricto de esta manera MUY POCAS veces). En Linux lo utilizamos mayormente por sus capacidades de proceso de archivos y flujos de texto, integrando en una sola herramienta las funcionalidades de otros comandos como sed y cut.
Comparación y ejemplos
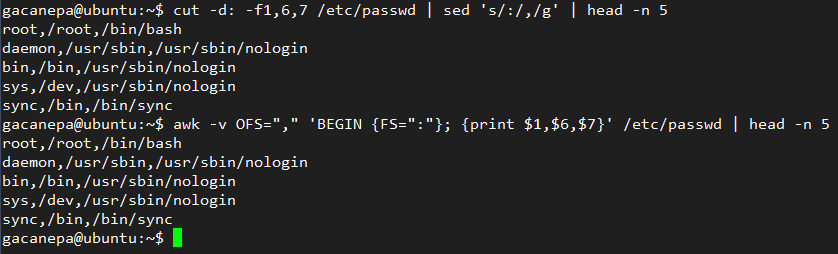
Por simplicidad, tomemos el conocido archivo /etc/passwd (el cual, como sabemos, contiene los datos de los usuarios del sistema uno por línea). En este archivo, los dos puntos (:) son utilizados como separador de campos. Veamos dos alternativas que podríamos utilizar para:
- extraer los campos 1, 6 y 7 (los cuales representan el nombre de usuario, su directorio home, y la ruta de su shell asignada, respectivamente), y
- cambiar el separador de campos por la coma (,)
Con cut y sed, podríamos hacer lo siguiente:
[pastacode lang=»bash» manual=»cut%20-d%3A%20-f1%2C6%2C7%20%2Fetc%2Fpasswd%20%7C%20sed%20’s%2F%3A%2F%2C%2Fg'» message=»» highlight=»» provider=»manual»/]
Mientras que con awk:
[pastacode lang=»bash» manual=»awk%20-v%20OFS%3D%22%2C%22%20’BEGIN%20%7BFS%3D%22%3A%22%7D%3B%20%7Bprint%20%241%2C%246%2C%247%7D’%20%2Fetc%2Fpasswd» message=»» highlight=»» provider=»manual»/]
Como podemos observar, los resultados son idénticos en ambos casos (en la Fig. 1 mostramos solamente las primeras cinco líneas de la salida por una cuestión de espacio):
Veamos un poco de qué se trata el comando anterior:
- La opción
-vseguida del argumentoOFS=","nos permite especificar como variable el separador de campos de salida (de Output Field Separator). En este caso deseamos utilizar la coma. - Entre comillas simples, con
'BEGIN {FS=":"}; {print $1,$6,$7}'decimos que los campos de la entrada están delimitados por dos puntos, y que deseamos mostrar (print) únicamente los campos n° 1, 6, y 7. - Finalmente, especificamos el archivo de entrada (/etc/passwd)
A primera vista, el uso de awk puede parecer más complejo. Sin embargo, es más potente ya que incluye de forma nativa las funcionalidades de muchos otros comandos. En el próximo post compartiremos otros ejemplos que nos ayudarán a demostrarlo. ¡Nos leemos en breve!