
En este post y en el próximo aprenderemos sobre la manera en que se implementa la tecnología conocida como RAID en Linux. Acrónimo de Redundant Array of Independent Disks, RAID consiste en una solución de almacenamiento que combina dos o más discos en una misma unidad lógica a fin de proveer redundancia de datos y/o aumentar el rendimiento de las operaciones de lectura o escritura. Sin embargo, ambas características dependen de la manera en que los discos se hayan organizado en lo que se denomina un nivel (puede pensarse como un tipo) de RAID dado.
Nota: Las imágenes ilustrativas que se encuentran a continuación han sido tomadas de Wikipedia.
Tres niveles de RAID en Linux
Aunque hay más opciones de acuerdo a las necesidades que tengamos, presentaremos solamente 3 niveles de RAID para introducir el tema:
RAID 0
Conocido también por su nombre en inglés stripe (debido a que distribuye los datos de forma pareja entre dos o más discos, tal como se muestra en la Fig. 1), este nivel de RAID provee un aumento en el rendimiento de las operaciones de lectura pero no provee tolerancia a fallos. Requiere de al menos dos discos para implementarse, y el tamaño resultante es igual a la suma del tamaño de cada disco.
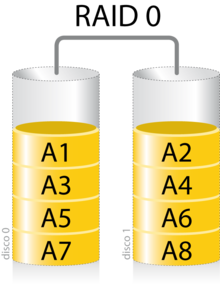
RAID 1
Conocido como mirror (espejo), este arreglo de discos provee redundancia de datos al escribirlos simultáneamente en dos discos, de manera separada (ver Fig. 2). Esto permite que si uno de los discos experimenta un fallo, la misma información está disponible en el otro. Sin embargo, impacta negativamente en el rendimiento de escritura ya que un dato tiene que ser escrito dos veces. Al reemplazar el disco defectuoso por uno nuevo se puede reconstruir el arreglo y copiar la información en el mismo. Requiere de al menos dos discos para implementarse, y el tamaño resultante es igual al disco de menor tamaño.

RAID 1+0
También llamado RAID 10, este nivel de RAID es una especie de «combinación» de los dos anteriores: consiste en un RAID 0 (stripe) de dos arreglos RAID 1 (mirror), tal como se aprecia en la Fig. 3:

Como es de esperar, este arreglo provee tanto una mejora en el rendimiento general de lectura y escritura como redundancia, aunque admite como máximo el fallo de un disco en cada espejo. El tamaño resultante es igual a la suma de la capacidad de los dos RAIDs 1.
En el post siguiente haremos referencia a la implementación práctica de RAID en Linux por software, y mostraremos un ejemplo de cada uno de los niveles detallados aquí. ¡Nos leemos en breve!