
¿Para qué nos sirve el unir y ordenar líneas en archivos de texto? Es muy útil a la hora de procesar archivos de texto en Linux. Al crear registros con la información que encontremos en los mismos, a menudo necesitaremos disponer de herramientas que nos permitan presentar dichos datos en un formato amigable, o que facilite su inserción en una base de datos, por nombrar algunos ejemplos útiles. Para facilitarnos esta tarea disponemos -además de los comandos vistos en posts anteriores- de tres herramientas que no deben faltarle a ningún administrador de sistemas: paste (para unir líneas), sort (ordenar líneas), y uniq (mostrar u omitir líneas repetidas).
Crear un archivo que pueda visualizarse en Microsoft Excel o LibreOffice
Para el ejemplo que realizaremos a continuación para unir y ordenar líneas en archivos de texto utilizaremos los archivos paises.txt y capitales.txt, los que contienen una lista de países de Sudamérica y sus respectivas capitales, como se muestra en la Fig. 1:
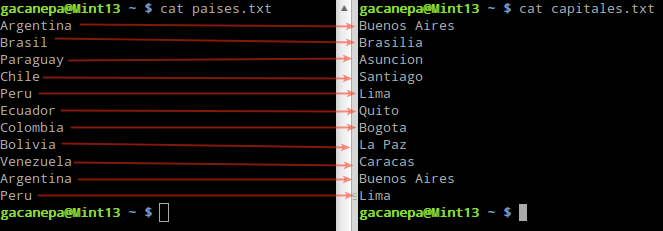
Unir y ordenar líneas en archivos de texto
El primer paso consistirá en unir ambos archivos línea a línea en uno solo, llamado datos.txt. Para hacerlo, utilizaremos paste y le indicaremos que utilice la coma como separador de contenido mediante la opción -d:
[pastacode lang=»bash» manual=»paste%20-d%2C%20paises.txt%20capitales.txt%20%3E%20datos.txt» message=»» highlight=»» provider=»manual»/]
Si mostramos el archivo datos.txt, veremos que hay dos líneas repetidas (Argentina y Perú con sus capitales).
Ordenar el archivo y omitir líneas repetidas
Para ordenar el archivo por país (primer campo) y eliminar las líneas repetidas, usaremos sort y uniq:
[pastacode lang=»bash» manual=»cat%20datos.txt%20%7C%20sort%20%7C%20uniq» message=»» highlight=»» provider=»manual»/]
o sort con su opción -u
[pastacode lang=»bash» manual=»sort%20-u%20datos.txt» message=»» highlight=»» provider=»manual»/]
obteniendo idénticos resultados como muestra la Fig. 2:
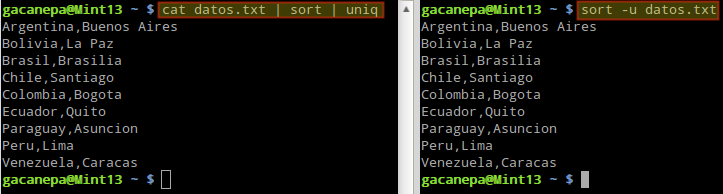
Con la primera variante es necesario utilizar sort ANTES que uniq debido a que este último comando puede mostrar u omitir las líneas repetidas adyacentes únicamente (por ese motivo, es necesario que realicemos el ordenamiento en primer lugar).
Ordenar líneas utilizando otro campo como referencia
Si quisiéramos ordenar utilizando como referencia las capitales en vez de los países, podríamos usar las opciones -k y -t para indicar el campo (en este caso sería el 2) y el separador de campos (la coma en este ejemplo):
[pastacode lang=»bash» manual=»sort%20-u%20-k%202%20-t%2C%20datos.txt» message=»» highlight=»» provider=»manual»/]
El resultado debería ser el siguiente:
Paraguay,Asuncion Colombia,Bogota Brasil,Brasilia Argentina,Buenos Aires Venezuela,Caracas Bolivia,La Paz Peru,Lima Ecuador,Quito Chile,Santiago
Utilizando un nuevo operador de redirección podemos guardar el resultado del último comando en final.csv:
[pastacode lang=»bash» manual=»sort%20-u%20-k%202%20-t%2C%20datos.txt%20%3E%20final.csv» message=»» highlight=»» provider=»manual»/]
y visualizarlo en LibreOffice Calc, como vemos en la Fig. 3:
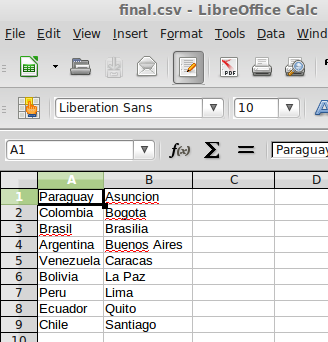
Al realizar las operaciones de unir y ordenar líneas en archivos de texto, tengamos en cuenta que los archivos delimitados por comas (comúnmente llamados csv, por la extensión más común que utilizan) pueden visualizarse en cualquier programa de hojas de cálculo.
¡Hasta el próximo post!
Un comentario en «Unir y ordenar líneas en archivos de texto»
¡Excelente aporte amigo!
Saludos